人工智能基础
搜索
组成
- Agent 智能体:感知环境并对环境采取行动
- State 状态:智能体和其环境的配置
- Initial state 初始状态
- Actions 行动
- 可供选择的操作
- Action(s) 行动集合
- Transition model 状态转移模型
- 描述某state某Action后的状态
- Result(s,a)表示为一个状态转移函数,它将当前的状态和一个输入映射到下一个状态
- State space 状态空间:从初始状态出发,通过行动序列可以到达的状态集合
- Goal test 目标测试
- Path cost function 路径成本
结果输出
- Solution 结果:行动序列
- Optimal solution 最优结果:具有最低路径成本
数据格式-Node
a data structure that keeps track of
- a state
- a parent (node that generated this node)
- an action (action applied to parent to get node)
- a path cost (from initial state to node)
在人工智能中,Node节点通常指的是神经网络中的一个计算单元或神经元(neuron),它可以接收一组输入值并输出一个输出值,从而完成神经网络的计算和推断任务。每个Node节点通常与其他节点连接,形成一个复杂的网络拓扑结构。
求解方法
Tree
- 从一个具有初始状态的边界(类)开始
- 如果边界(fringe)空,则返回搜索失败failure
- 如果边界中有节点,移出一个节点
- 检查是否为目标节点,如果是,返回值
- 如果不是,向边界中放入子节点
- 重复2-5
graph
如果出现回路,则树检索可能失败。
- 从一个具有初始状态的边界(类)开始
- 同时从一个空探索集开始
- 如果边界(fringe)空,则返回搜索失败failure
- 如果边界中有节点,移出一个节点
- 检查是否为目标节点,如果是,返回值
- 如果不是,原节点放入探索集。向边界中放入不在探索集里的子节点
- 重复3-6
优先算法
当集合中有多个元素时,需要优先算法。
DFS深度优先,后入先出。由于后入为子节点,所以为深度搜索。搜索完返回最近父节点。
BFS广度优先,先进先出。可视化为层层搜索。
UCS一致代价搜索,边界是一个优先队列,按照累计代价排序取出。 按后向成本:路径成本搜索
对于有限状态空间,深度优先搜索是完备可解的。但不一定是最优解。其时间复杂度为$O(b^m)$总结点数,空间复杂度为最大链条深度(只存储一条链条,每一个节点之外只计入一层子节点),为$O(bm)$。
对于有限状态空间,广度优先搜索是完备可解的。但不一定是最优解。其时间复杂度为$O(b^s)$总结点数,空间复杂度为最大链条深度(只存储一条链条,每一个节点之外只计入一层子节点),为$O(b^s)$。
启发式函数
曼哈顿距离
欧氏距离:直线距离
曼哈顿距离:区块距离、欧几里得空间上固定直角坐标系上两点连线(欧氏距离)投影在坐标轴上的距离和
贪心算法Greedy best
根据启发式函数的估计,扩展最接近目标节点的搜索算法
按前向成本搜索
A*搜索
同时按后向和前向成本搜索$f(n)$
\[\begin{align} f(n)=h(n)+g(n) \end{align}\]A*搜索表现为可能搜索到一半突然返回父节点。
如果A*搜索是最优的,则启发式函数必须满足条件(设真实前向成本为$h^{\star}(n)$)
- 可纳性:$0\le h(n)\le h^{\star}(n)$
- 一致性:$h(A)\le cost(A~to~C)+h(C)$
A*搜索是最优的。通常来说,启发式函数是对松弛问题的解。
对抗搜索
Assumption
- 博弈
- 零和
- 确定性游戏
井字棋博弈树
- $S_0$:初始状态
- $PLAYER(s)$:玩家判断,决定在该状态下的行动者
- $ACTION(s)$:行动判断,决定在该状态下可能的行动空间
- $RESULT(s,a)$:结果函数,起始状态和行动决定了结果状态,即状态s在操作a下的结果。
- $TERMINAL(s)$:检查是否终止
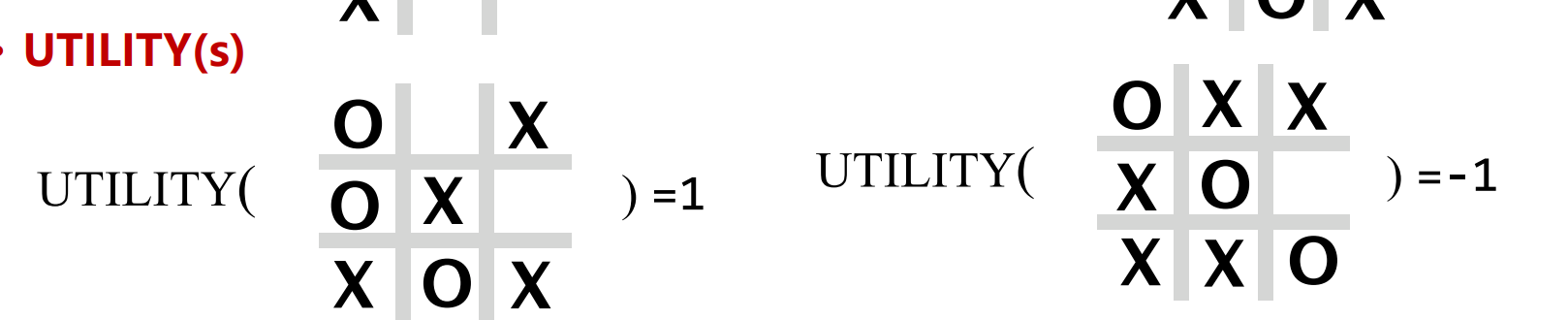
- $UTILITY(s)$:效用函数/目标函数/代价函数,描述结束状态的胜负优劣。
零和博弈:智能体的效用函数相反。 因此在自己回合效用函数应当最大,而对手回合效用函数应当最小
一般博弈:智能体效用独立。
实际操作过程:从结果状态开始,遍历每一个可能博弈路径,交替使用MaxValue和MinValue函数,找到最优解。类似DFS。
最优,时空复杂度与DFS相同。
时间复杂度:$O(b^m)$,空间复杂度$O(bm)$
$\alpha-\beta$剪枝
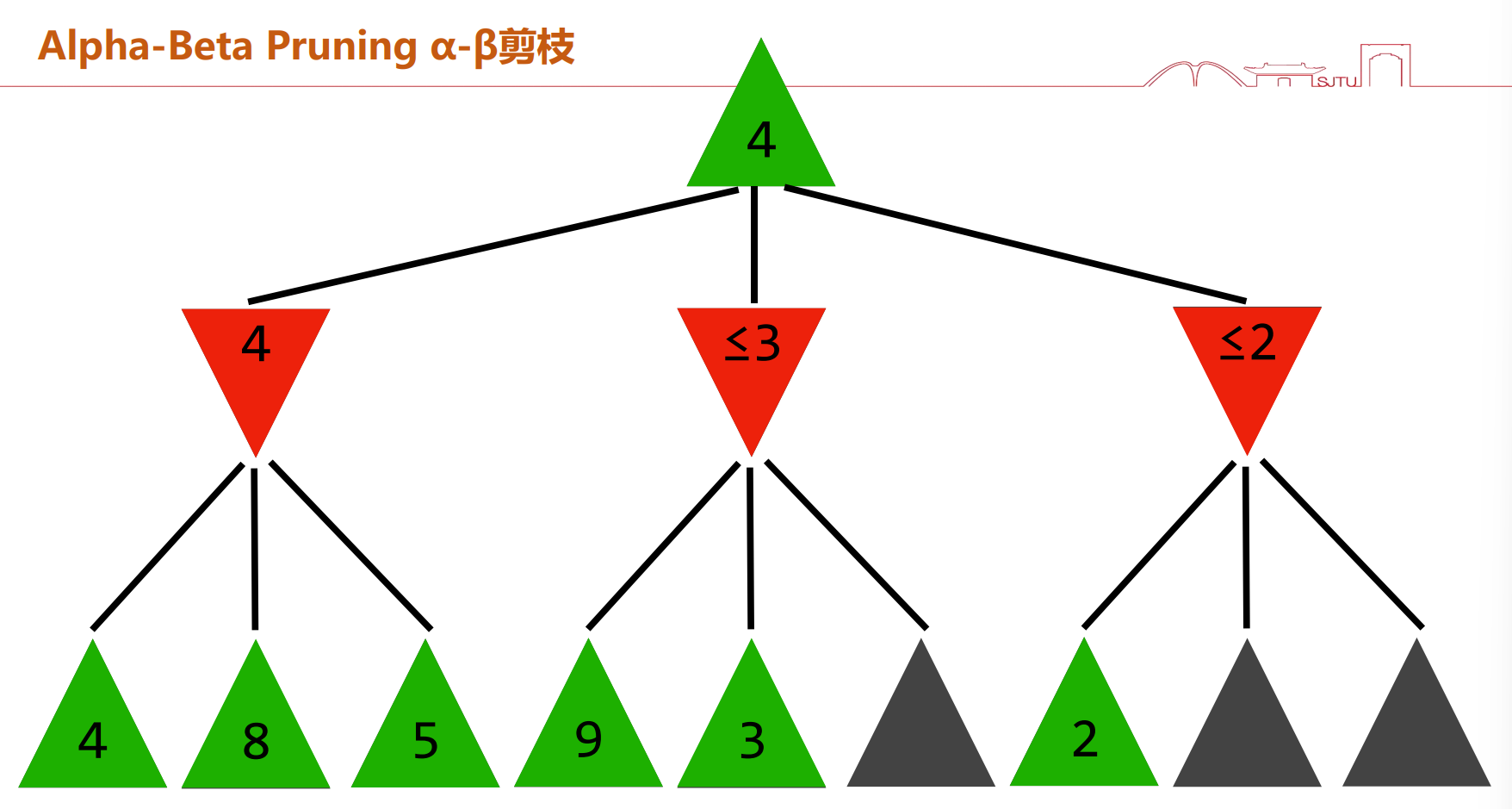
对于一个结点MIN(敌人结点),若能估计出其倒推值的上界(遍历的值),若这个上界不大于(小于)MIN的父节点(最大收益),及时停止那些已无必要再扩展的结点……
比如说在这里,红色作为max节点,我们至少需要一个$\ge4$的节点,但是对于每一个红色节点下的min节点,其提交的是最小值,所以若$Max(min(3))\le4$则可以抛弃。
Expectimax
Expectimax的伪代码与minimax很相似,就是把最小效益换成了期望效益,这是因为最小化节点被替换成了机会节点。
需要重点注意的是,必须要遍历机会节点的所有子节点——不能再像minimax中一样进行剪枝。与minimax中求最大值或最小值时不同,每个值都会影响expectimax计算的期望值。不过,当我们已知节点有限的取值范围时,剪枝也是有可能的。
不确定性
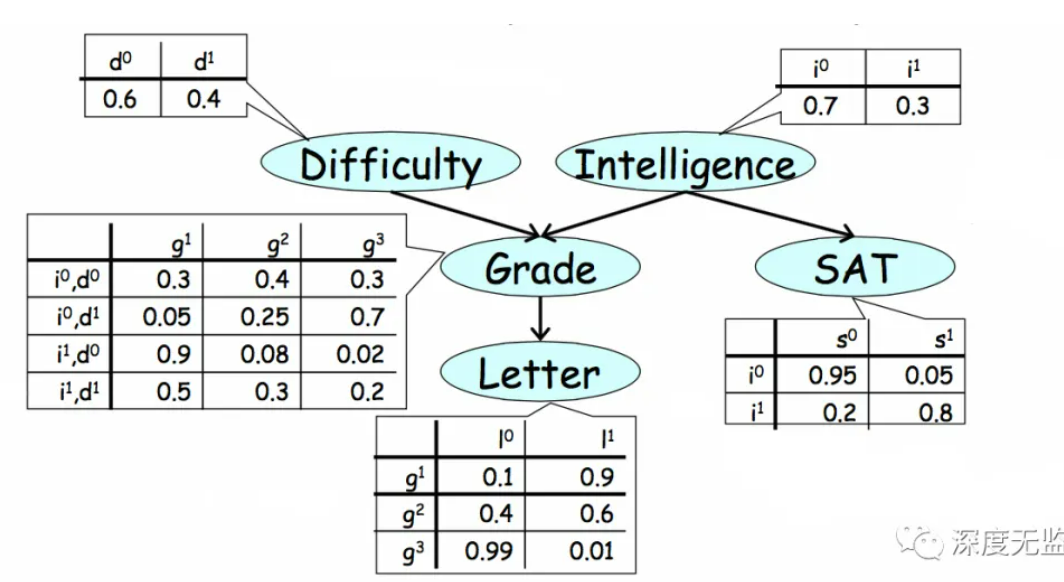
Bayes’ Net
联合分布表太大,无法存储。贝叶斯网络使用简单的局部分布来描述复杂的联合分布。
链式法则(全概率公式)
\[\begin{align} P(x_1,x_2,\dots x_n)=\prod_iP(x_i|x_1\dots x_{i-1}) \end{align}\]假设条件独立,即只考虑直接因素:
\[\begin{align} P(x_i|x_1\dots x_n)=P(x_i|parent(x_i)) \end{align}\]贝叶斯网络本质是表示随机变量之间依赖关系的数据结构:
- 有向图
- 代表单随机变量的节点
- 箭头代表关系
- 每个节点上具有随机概率
真实的因果关系适合贝叶斯网络的构建。但是贝叶斯网络中的关系并不一定代表因果关系,而只是代表相关性。有向图的拓扑结构实际上编码了条件独立性。
D-separation
Causal Chain
为有因果关系(或非条件独立)的变量或命题则用箭头来连接。若两个节点间以一个单箭头连接在一起,表示其中一个节点是“因(parents)”,另一个是“果(children)”,两节点就会产生一个条件概率值。
| 例如,假设节点E直接影响到节点H,即E→H,则用从E指向H的箭头建立结点E到结点H的有向弧(E,H),权值(即连接强度)用条件概率P(H | E)来表示。 |
三联体的因果关系为:
\[\begin{align} X\longrightarrow Y\longrightarrow Z \end{align}\]有概率公式为:$P(X,Y,Z)=P(X)P(Y\vert X)P(Z\vert Y)$。
- 在不知道Y的时候:
- 知道Y的时候:
链条上的证据可以阻止影响。
Common cause
三联体的因果关系为:
\[\begin{align} X\longleftarrow Y\longrightarrow Z \end{align}\]有概率公式为:$P(X,Y,Z)=P(Y)P(X\vert Y)P(Z\vert Y)$。
- 在不知道Y的时候:
- 知道Y的时候:
观察效果之间的原因可以阻隔影响。
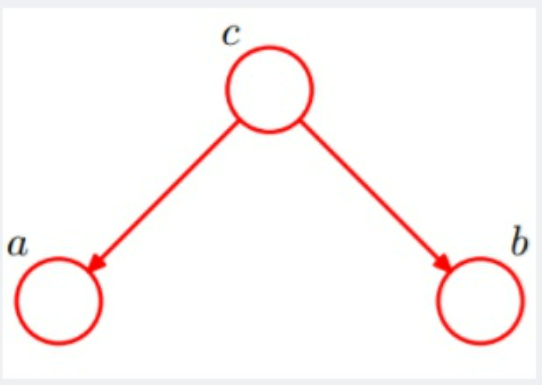
| P(a,b,c) = P(a)P(b)P(c | a,b)成立,即在c未知的条件下,a、b被阻断(blocked),是独立的,称之为head-to-head条件独立。 |
| 在c未知的时候,有:P(a,b,c)=P(c)*P(a | c)*P(b | c),此时,没法得出P(a,b) = P(a)P(b),即c未知时,a、b不独立。 | ||||||
| 在c已知的时候,有:P(a,b | c)=P(a,b,c)/P(c),然后将P(a,b,c)=P(c)*P(a | c)*P(b | c)带入式子中,得到:P(a,b | c)=P(a,b,c)/P(c) = P(c)*P(a | c)*P(b | c) / P(c) = P(a | c)*P(b | c),即c已知时,a、b独立。 |
c未知时,有:P(a,b,c)=P(a)*P(c a)*P(b c),但无法推出P(a,b) = P(a)P(b),即c未知时,a、b不独立。 c已知时,有:P(a,b c)=P(a,b,c)/P(c),且根据P(a,c) = P(a)*P(c a) = P(c)*P(a c) - \[\begin{align} P(a,b|c) = \frac{P(a,b,c)}{P(c)}=\frac{P(c)P(a|c)P(b|c)}{P(c)}\\ =P(a|c)P(b|c)\\ \end{align}\]
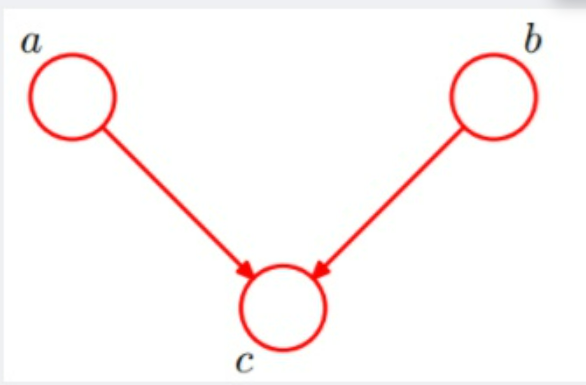
Common Effect
三联体的因果关系为:
\[\begin{align} X\longrightarrow Z\longleftarrow Y \end{align}\]有概率公式为:$P(X,Y,Z)=P(Z\vert X,Y)P(X,Y)$。
被观察的结果会导致原因不独立。
D separation Algorithm

根据之前讨论,需要额外注意的是Common Effect,也称为V型结构。V型结构在结果节点(也被称为碰撞点collider)及其子节点不在条件集(确定量集)中时,相当于一个阻碍,而在条件集中时不再是一个阻碍。
Active Trials
当下面两个条件中有一个被满足,说明一个Trail(X1-X2-…-Xn)关于Z是Active的: (1)对于任意V型结构:Xi->X<-Xj,X属于Z,或X的子事件属于Z (2)没有Xi属于Z(Z不为空)
对于其他的结构,条件集中的一个点就是一个阻碍。无阻碍的路径被称为活跃(active)
\[\begin{align} \newcommand{\indep}{\perp\!\!\!\perp}\\ X_i\indep X_j|{X_{k_1},\dots X_{k_n} } \end{align}\]找出其中所有路径,如果有acitve路径,则不能保证条件独立。
Bayes’ Inference
- X: 需要查询的事件
- E:条件集/已观察的事件
- Y:隐藏事件
- 目标查询$P(X\vert E)$
枚举推断
\[\begin{align} P(X|e)=\alpha P(X,e)=\alpha\sum_yP(X,e,y) \end{align}\]$\alpha$是一个归一化系数。
近似推断
其实就是抽样调查。
不过我们可以先进一点,在抽样中加入拒绝抽样,排除不需要的部分。
祖先采样(步步推导):
拒绝采样:
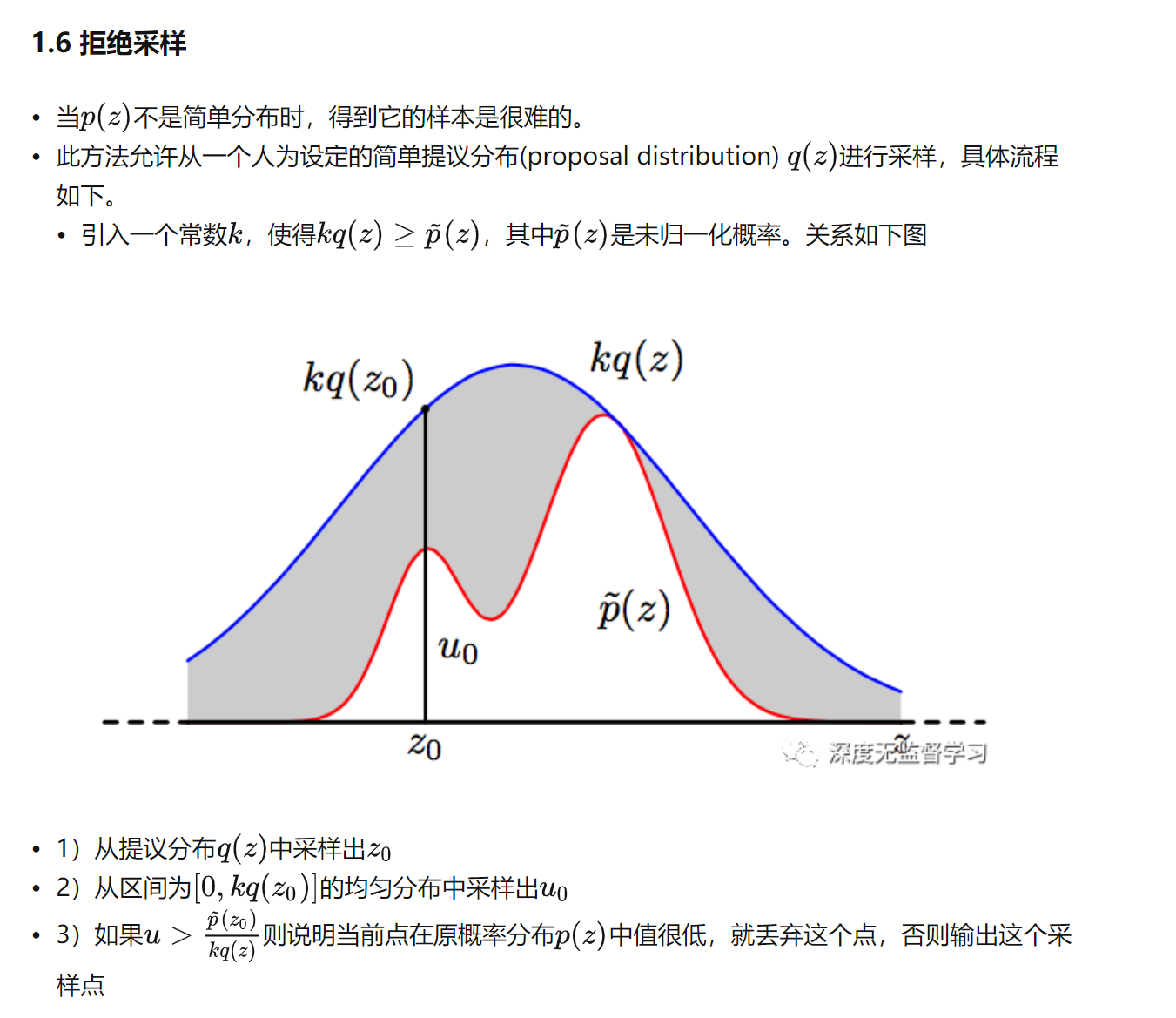
固定证据变量后继续采样。
Markov Model
假设:当前状态只取决于有限的固定数量的前状态。
马尔科夫链:遵循马尔可夫假设的随机变量的列。
约束满足问题CSP
约束满足是NPhard问题。
- 约束变量set of variables
- 取值范围,变量的搜索空间
- 约束条件
解决方法:是做搜索
- 初始化(空状态)
- 行动:试探赋值
- 过渡模型:显示添加后的变化
- 目标测试:检查约束标记
- 路径成本:所有
弧相容

Backtracking Search
- 规定变量的顺序,并按照这个顺序选择变量的赋值。因为赋值是可以互换的(例如,令WA=Red,NT=Green 等价于 令NT=Green,WA=Red),这是有效的。
- 在给变量选择赋值时,只选择不与已经分配了的值冲突的赋值。如果不存在这样的值,回溯并返回前一个变量,并改变其赋值。
每次搜索只对一个约束标量调查,如果碰到域为0,回溯。
过滤
前向检查Forward Checking
相对于后向检查,缩减域而非直接赋值。
弧相容

最坏时间复杂度为$O(ed^3)$其中e为弧数量,d为最大域的大小。
k-consistency
弧相容即2-相容。
- 设置一个check队列
- 根据check队列对每一个变量进行约束判断
- 如果没有变化(缩减取值范围),则弧一致,不用管
- 如果发生缩小,则移至队列末尾,待查
- 如果取值范围完全退化,则抛弃变量
排序
MRV最小剩余值排序
相比FC,优先选择域最小的变量进行检查。
LCV最小约束值
优先选择约束最小的变量。
结构
树状结构
具体来说,如果我们要解决一个树形结构的CSP(tree-structured CSP)(其约束图中没有环),我们能将找到一个解的时间从 $O(d^N)$ 减少到 $O(nd^2)$ ,变量的数量是线性的。用树形结构CSP算法能做到这一点,其概述如下:
- 首先,在CSP的约束图中任选一个节点来作为树的根节点(具体选哪一个并不重要,因为基础图论告诉我们一棵树的任一节点都可以作为根节点)。
- 将树中的所有无向边转换为指向根节点反方向的有向边。然后将得到的有向无环图线性化(linearize)(或拓扑排序(topologically sort))。简单来说,这也就意味着将图的节点排序,让所有边都指向右侧。注意我们选择节点A作为根节点并让所有边都指向A的反方向,这一过程的结果是如下的CSP转换:
割集
将存在环结构CSP通过固定(讨论)一个点的变量,使其变为树状结构。
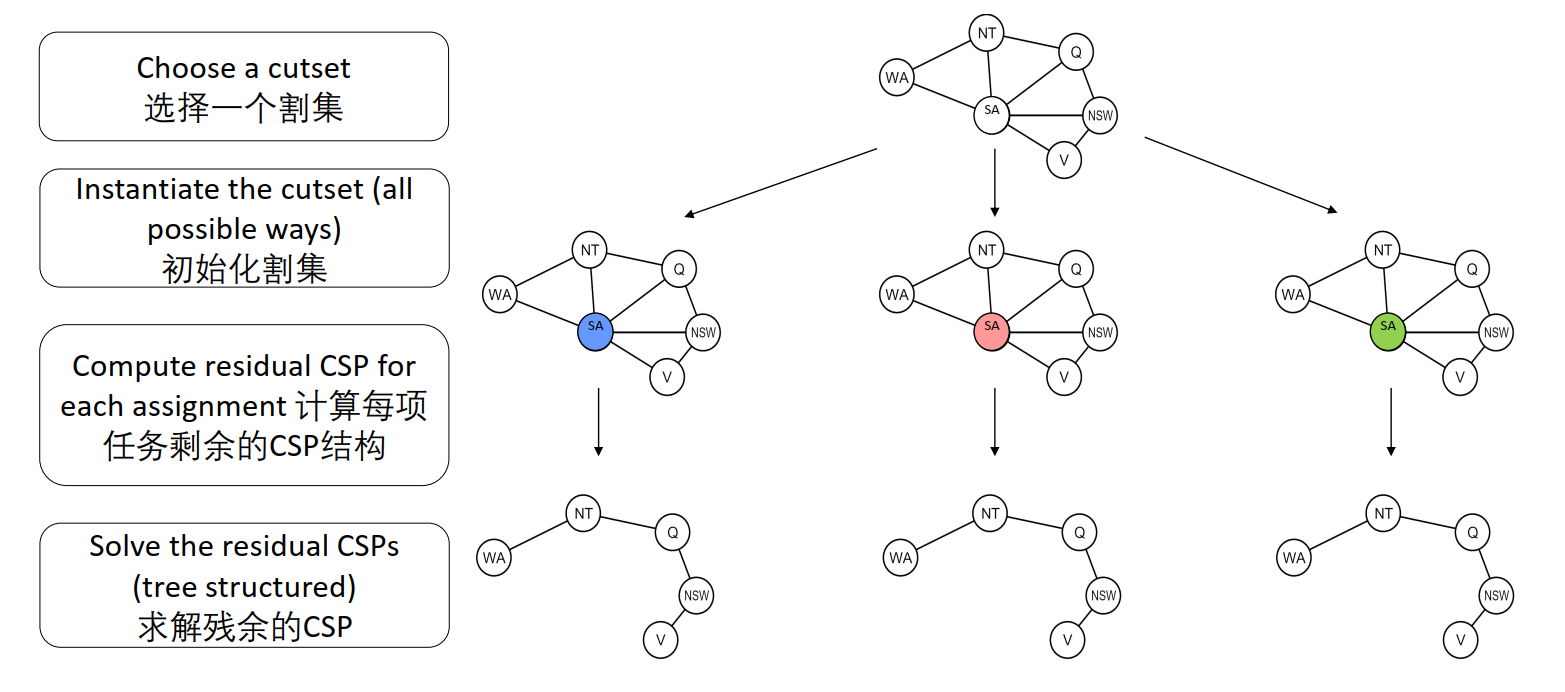
本地搜索
它的思想非常简单直接,但是相当有效。本地搜索通过迭代改进来工作——从一些随机的变量赋值开始,反复选择违反约束最多的变量并将其重置为违反约束最少的值(这一策略称为最小冲突启发式(min-conflicts heuristic))。通过这一策略,我们能既节省时间又节省空间地解决类似N皇后问题这样的约束满足问题。本地搜索对任意生成的CSP的运行时间几乎是常数并且成功率也非常高!然而,抛开这些优势,本地搜索并不具备完备性和最优性,所以并不一定能得到最优解。另外,有一个关键的比例,在其附近,本地搜索的代价极高。
爬山法
本质上是梯度下降法。
退火算法
与爬山法比较,是加入了一个随机因素的贪心算法。使用来源:metropolis准则(蒙特卡洛准则)。如果考虑一个权重w,则对于爬山法,其只接受$w<0$的改变,而对于退火算法,其算法为:
if(w<0){
accept;
}else if(w>randnum<0.0,1.0>){
accept;
}else unaccept;
遗传算法
Hopfield net
线性规划
有监督/无监督学习

神经网络
感知机
或
与
和
梯度下降
随机梯度下降
Mini batch descent
多层感知机
前馈神经网络
误差反向传播算法
深度神经网络
卷积神经网络
神经网络正则化
激活函数
损失函数
递归/循环神经网络
LSTM
强化学习
Markov Decision Process
定义:
- 状态集:$s\in S$
- 行动集:$a\in A$
转移函数:$T(s,a,s’)=P(s’ s,a)$ - 奖励函数:$R(s,a,s’)$
MDPs是不确定性的搜索问题。
马尔科夫链的数学本质:
\[\begin{align} P(S_{t+1}=s'|S_t=s_t,A_t = a_t,S_{t-1} = s_{t-1},A_{t-1}\dots)\\ =P(S_{t+1} = s'|S_t=s_t,A_t=a_t) \end{align}\]MDPs与马尔可夫过程的区别在于,增加了行动集。使得过程不再被提前确定。

效用函数
折扣因子
- 奖励总和最大化
- 偏爱现在的奖励而不是以后的
折扣因子作为一个对奖励的级数调整存在,有助于算法收敛。
Q-state
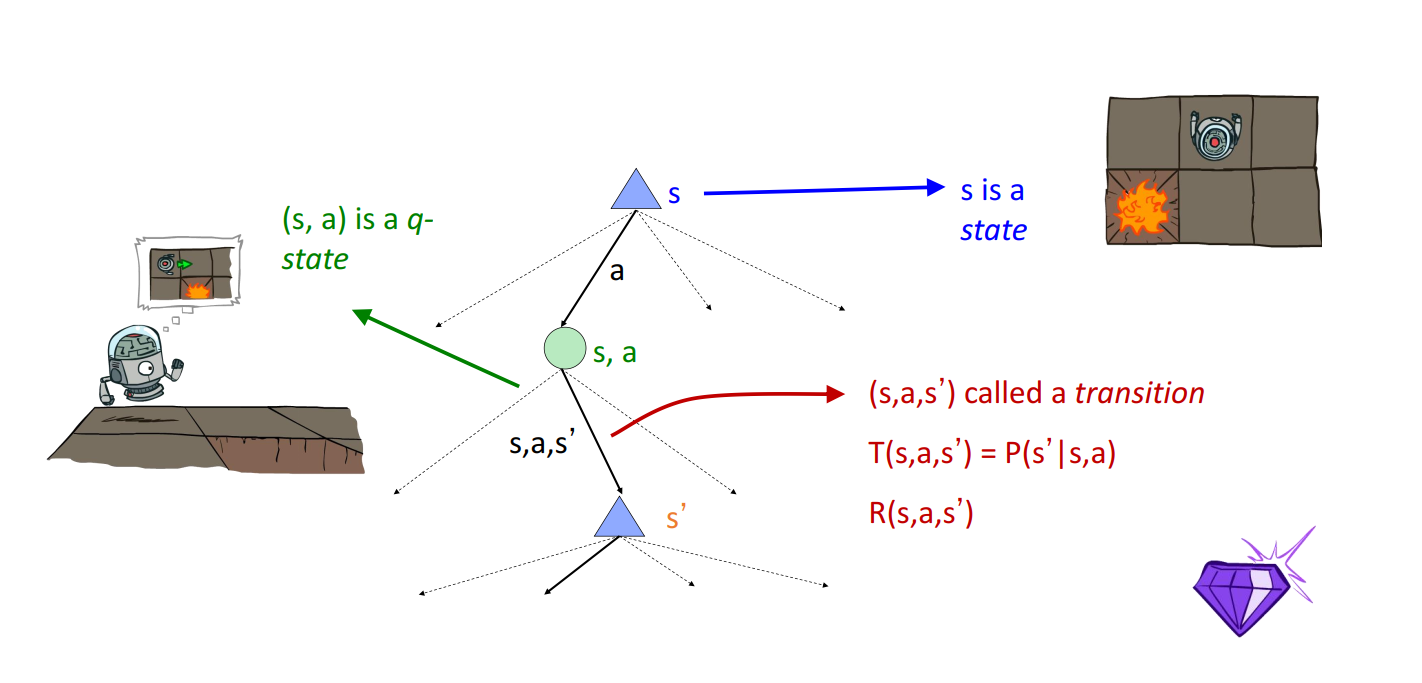
本质上是一个机会节点,携带了其子状态节点的权重。
优化变量
- 状态效用函数$V^*(s)$
- q状态的效用$Q^*(s,a)$
- 从s状态开始的最佳策略$\pi^*(s)$
价值递归定义:
\[\begin{align} V^*(s)=\mathop{max}\limits_{a}Q^*(s,a)\\ Q^*(s,a)=\sum_{s'}T(s,a,s')[R(s,a,s')+\gamma V^*(s')]\\ \therefore V^*(s)=\mathop{max}\limits_{a}\sum_{s'}T(s,a,s')[R(s,a,s')+\gamma V^*(s')] \end{align}\]值迭代
从$V_0(s)=0$开始
迭代使用贝尔曼方程
- \[\begin{align} V^*_{k+a}(s)\leftarrow\mathop{max}\limits_{a}\sum_{s'}T(s,a,s')[R(s,a,s')+\gamma V_k^*(s')] \end{align}\]
- 从初始状态价值开始同步迭代计算,最终收敛(后面会证明),整个过程中没有遵循任何策略。
- 注意:与策略迭代不同,在值迭代过程中,算法不会给出明确的策略。
- 迭代过程其间得到的价值函数,不对应任何策略。
- 值迭代是一个固定点迭代方法
提取策略:
\[\begin{align} \pi^*(s)=\mathop{argmax}\limits_{a}\sum_{s'}T(s,a,s')[R(s,a,s')+\gamma V_k^*(s')] \end{align}\]时间复杂度$O(s^2a)$速度很慢,策略可能早于数值收敛。
Q-迭代
由于策略更容易通过Q值得到:
\[\begin{align} \pi^*(s)=\mathop{arg max}\limits_aQ^*(s,a) \end{align}\]所以可以把值函数换为Q值函数得到新的迭代方程:
\[\begin{align} Q_{k+1}(s,a)\leftarrow\sum_{s'}T(s,a,s')[R(s,a,s')+\gamma \mathop{max}\limits_{a'}Q_k(s'a')] \end{align}\]策略迭代
固定一个策略action,$P(a_i s)=\delta_{0i}$ - 通过一步前瞻法求得此时的价值函数,本质上是去除了最大化计算的线性贝尔曼方程。
- 策略提升(本质是策略提取)
- 重复
强化学习
强化学习通常要面临的难题是,对于学习器,MDP四元组并非全部已知,即“无模型” (model-free)。最常见的情况是转移函数T未知以及奖赏函数R未知,这时就需要通过在环境中执行动作、观察环境状态的改变和环境给出的奖赏值来学出T和R。